Dans un élevage, quels animaux sélectionner pour donner naissance à la génération suivante ? Encore récemment, le choix des individus se fondait sur leurs performances propres et sur celles de leurs apparentés. Mise en place à la fin des années 2000, la sélection génomique est venue bouleverser les pratiques de sélection en permettant de prédire les performances des candidats à la reproduction par comparaison de leurs génotypes avec ceux d’individus d’une population de référence.
La lecture de cet article nécessite d'être familier avec les notions de valeur génétique, d'héritabilité, d'index, de progrès génétique et de sélection génétique « classique » qui sont développées dans l'article Introduction à l’amélioration génétique animale et exemples d’application aux élevages bovins laitiers.
La sélection des bovins laitiers avant la génomique
La sélection des animaux a commencé dès leur domestication, qui a débuté pour la plupart des espèces il y a entre 12 000 et 5 000 ans 1. En effet, les sociétés ont depuis longtemps choisi les animaux qu’elles gardaient pour procréer la génération suivante. Les critères de choix reposaient sur les phénotypes individuels : taille, puissance musculaire, couleur, cornes, docilité… À partir du XVIIIᵉ siècle, les premières races ont été constituées. Une race est un ensemble d’animaux respectant un standard phénotypique défini, en particulier la couleur, et que l’on fait se reproduire ensemble. Les éleveurs les plus passionnés par leur race ont constitué les premiers livres généalogiques dans lesquels les animaux sont identifiés et les parents enregistrés, de façon à pouvoir retracer leurs généalogies (pedigrees). En élevage bovin laitier, les premiers contrôles de performances, en particulier les pesées et les mesures de quantité de lait, sont organisés, fournissant des valeurs objectives pour la sélection. Au-delà des performances individuelles, la valeur de l’ascendance est également prise en compte, en particulier les qualités laitières de la mère pour le choix d’un taureau de race laitière.
La théorie de la génétique quantitative a été développée par des mathématiciens comme Ronald Fisher ou Sewall Wright, au début du XXᵉ siècle. Cette théorie définit la notion de valeur génétique. Pour un animal et un caractère donné, la valeur génétique correspond à deux fois l’espérance de l’écart entre les performances de ses descendants et la moyenne de la population. L’héritabilité est le rapport de la variance génétique (c'est-à-dire de la variance des valeurs génétiques) et de la variance phénotypique. Dans les années 40, Lanoy N. Hazel développe la théorie des index. Un index ou estimation de valeur génétique de précision maximale, est la combinaison linéaire des performances de l’individu et de tous ses apparentés, pondérées par des poids optimaux dépendant de l’apparentement avec l’individu indexé. Jusque dans les années 70, ces index ont été utilisés avec efficacité, mais ils ont plusieurs défauts importants : (a) les performances doivent être préalablement corrigées pour les effets de milieu et ces valeurs doivent être estimées précisément ; (b) les pondérations des performances doivent être recalculées pour chaque individu compte tenu de sa situation généalogique et ce calcul peut être complexe si le nombre et le type d’apparentés sont importants.
Chez les bovins laitiers, les vaches sont réparties dans des milliers d’élevages, chacun présentant ses propres conditions de milieu. À l’intérieur d’un troupeau, la pression de sélection est limitée, car l’essentiel des femelles nées doivent être gardées pour le renouvellement, et le choix des taureaux de monte naturelle, s’il est basé uniquement sur la performance de leur mère, est peu précis. Dans les années 1950, pour des raisons initialement sanitaires (la circulation des taureaux entre troupeaux était un vecteur de nombreuses maladies), l’insémination artificielle a connu un très grand développement. Cela a été aussi l’occasion de concevoir des programmes de sélection très efficients, à l’échelle de la population et non plus uniquement au sein du troupeau. Une partie importante des élevages contribue à une base de données indispensable à la sélection : les animaux sont identifiés, leurs généalogies sont connues, leurs performances sont mesurées pour des caractères variés. Ces données sont centralisées et servent à calculer les index. De jeunes taureaux sont d’abord sélectionnés à partir des meilleurs parents et sont élevés dans des centres. À leur puberté, ils sont mis en testage sur descendance, c’est-à-dire utilisés en insémination artificielle pour produire une centaine de filles (dans autant de troupeaux) dont les performances sont mesurées avec celles de leurs contemporaines. Ces performances permettent d’estimer des index sur descendance très précis et d’identifier les taureaux élites que l’on diffuse ensuite largement dans la population. Ce système présente plusieurs avantages : insémination par semence congelée, ce qui permet de dissocier la production de semence de son utilisation et de diffuser la semence dans de très nombreux élevages ; apport d’une génétique de haute qualité à tous les éleveurs et réalisation d’un progrès génétique élevé ; haute précision des index limitant le risque de diffusion d’une génétique de mauvaise qualité. Ce mode de sélection a aussi des inconvénients : tout d’abord la longueur du cycle de sélection, au moins 6 ans entre la procréation d’un taureau et sa sélection et diffusion après testage ; son coût, de plusieurs centaines de milliers d’euros par taureau sélectionné, ce qui impose ensuite une diffusion large pour que le programme soit économiquement durable.
Entre les années 1960 et 2009, le testage sur descendance a été la règle pour estimer les index des taureaux laitiers. Toutefois, il a énormément évolué grâce aux progrès de l’informatique et des statistiques. De grandes bases de données de pedigrees et de phénotypes ont été constituées. En France, c’est l’Institut national de recherche pour l’agriculture, l’alimentation et l’environnement (Inrae) qui héberge la base nationale zootechnique depuis 1970. En 1973, Charles Henderson propose la méthode BLUP (Best Linear Unbiased Prediction) qui permet d’estimer simultanément les effets génétiques et les effets de milieu. Le BLUP est étendu au modèle « individuel » qui formalise un système d’équations pour estimer la valeur génétique de tous les animaux, mâles ou femelles, de la population analysée. Si la sélection a bénéficié de perfectionnements continus grâce aux progrès de l’informatique, le testage sur descendance des taureaux est resté la règle jusqu’à la fin des années 2000.
En 2009 a été mise en œuvre la sélection génomique décrite dans cet article.
Le développement de la génomique et des outils de génotypage
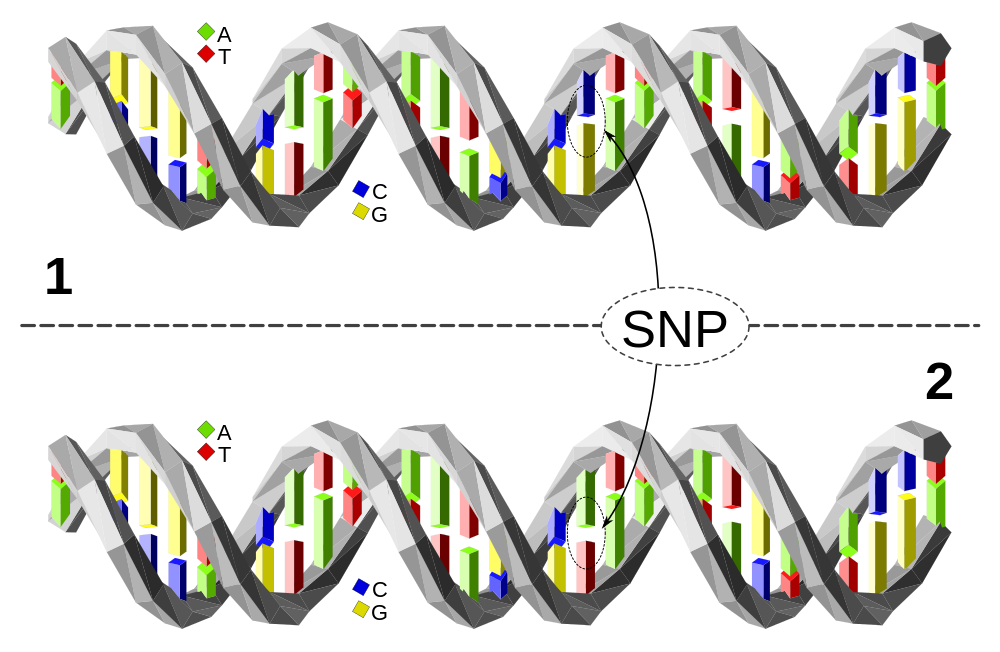
Le long de cette courte séquence, l’ADN des individus 1 et 2 est identique à une paire de nucléotides près : l’individu 1 possède le couple C-G tandis que l’individu 2 présente le couple A-T. Cette variation d’une paire de nucléotides, si elle est présente chez au moins 1 % de la population, est appelée polymorphisme mononucléotidique (SNP en anglais, à prononcer « snip »). En fonction de l’endroit où se situe la variation elle peut avoir un effet sur le phénotype ou non.
La sélection génomique consiste à sélectionner des reproducteurs sur la base de leur valeur génétique prédite à partir de marqueurs génétiques répartis sur le génome. Cette approche inventée en 2001 1 est restée d’abord sans application, faute de disposer des outils génomiques adéquats. La sélection génomique nécessite en effet de pouvoir génotyper les individus pour un grand nombre de marqueurs couvrant tout le génome. Des progrès considérables ont été réalisés au cours des années 2000 dans ce domaine technologique. Le génome d’un nombre croissant d’espèces d’élevage a été séquencé, donnant accès à des dizaines de millions de variants génétiques. Les plus fréquents sont des SNP (Single Nucleotide Polymorphism ou polymorphisme mononucléotidique) qui résultent de la substitution d’un nucléotide par un autre (Figure 1).
Des dispositifs dénommés « puces à SNP » ont été élaborés et commercialisés par deux compagnies principales, Illumina et Affymetrix. Ces puces permettent de génotyper des individus pour un grand nombre de variants simultanément. L’ADN est extrait à partir d’un tissu de l’individu (sang, cartilage, muqueuse buccale ou nasale, sperme…), amplifié par PCR, et hybridé de manière spécifique sur la puce. L’hybridation est associée à un signal lumineux, variable selon l’allèle. Ce signal est lu par un scanner à haute résolution et permet de déduire le génotype de l’individu, AA, AB ou BB. Des puces à SNP, permettant de typer plusieurs dizaines de milliers de marqueurs simultanément sont disponibles pour la majorité des espèces d’élevage. Chez le bovin, la première puce de référence commercialisée en 2008 permettait de tester 54 000 SNP simultanément. Elle a été complétée par deux puces à haute (777 000) et basse densités (7000), bon marché. De nombreuses autres puces ont été créées depuis (Figure 2).
Principe de la sélection génomique
Les caractères que l’on cherche à sélectionner ont un déterminisme généralement complexe : ils sont soumis à l’effet de nombreux gènes, généralement inconnus, et à des effets du milieu. La valeur génétique d’un individu pour un trait donné reflète l’effet de l’ensemble des gènes impliqués dans l’expression de ce trait. Depuis les années 1950, pour sélectionner de façon rationnelle, on a retenu les individus aux valeurs génétiques les plus élevées, estimées à partir des phénotypes mesurés sur les candidats eux-mêmes ou sur leurs apparentés proches. La sélection utilise donc des phénotypes et des généalogies, qui sont combinés dans un modèle mathématique qui corrige les phénotypes pour les effets de milieu et pondère de façon optimale l’ensemble des phénotypes pour estimer les valeurs génétiques.
Avec l’émergence des marqueurs génétiques (en particulier les SNP, voir Figure 1), les approches de prédiction des valeurs génétiques ont cherché à utiliser ce nouveau type d’information. Dans un premier temps, les régions du génome les plus importantes dans le déterminisme génétique d’un caractère (appelées QTL pour quantitative trait locus) ont été détectées pour les utiliser ensuite en sélection. Les marqueurs génétiques, qui n’ont généralement pas d’effet biologique propre, peuvent être situés à proximité de gènes ayant un effet sur les caractères. Du fait de leur proximité sur le génome, les marqueurs sont transmis avec les gènes et ont un effet statistique apparent, celui de la région qui les entoure. Sélectionner sur les allèles des marqueurs présentant un effet apparent favorable conduit à sélectionner les allèles favorables de ces gènes. Lorsqu’on sélectionne sur un petit nombre de régions, on parle de sélection assistée par marqueurs.
Cependant, pour la plupart des caractères, chaque QTL n’explique qu’une faible fraction de la variabilité génétique, de sorte que la sélection assistée par marqueurs a une efficacité limitée. En 2001, Meuwissen et ses collaborateurs ont proposé une nouvelle approche, utilisant des marqueurs couvrant l’ensemble du génome, ou sélection génomique 1. Le principe est relativement simple : une grande population de référence, phénotypée et génotypée, permet d’établir les relations statistiques entre génotype et phénotype (Figure 3). Autrement dit, cette méthode estime à partir de ces données les effets apparents de tous les marqueurs génotypés. Ces effets apparents sont ensuite appliqués à des candidats génotypés et leur somme constitue une prédiction de leur valeur génétique.
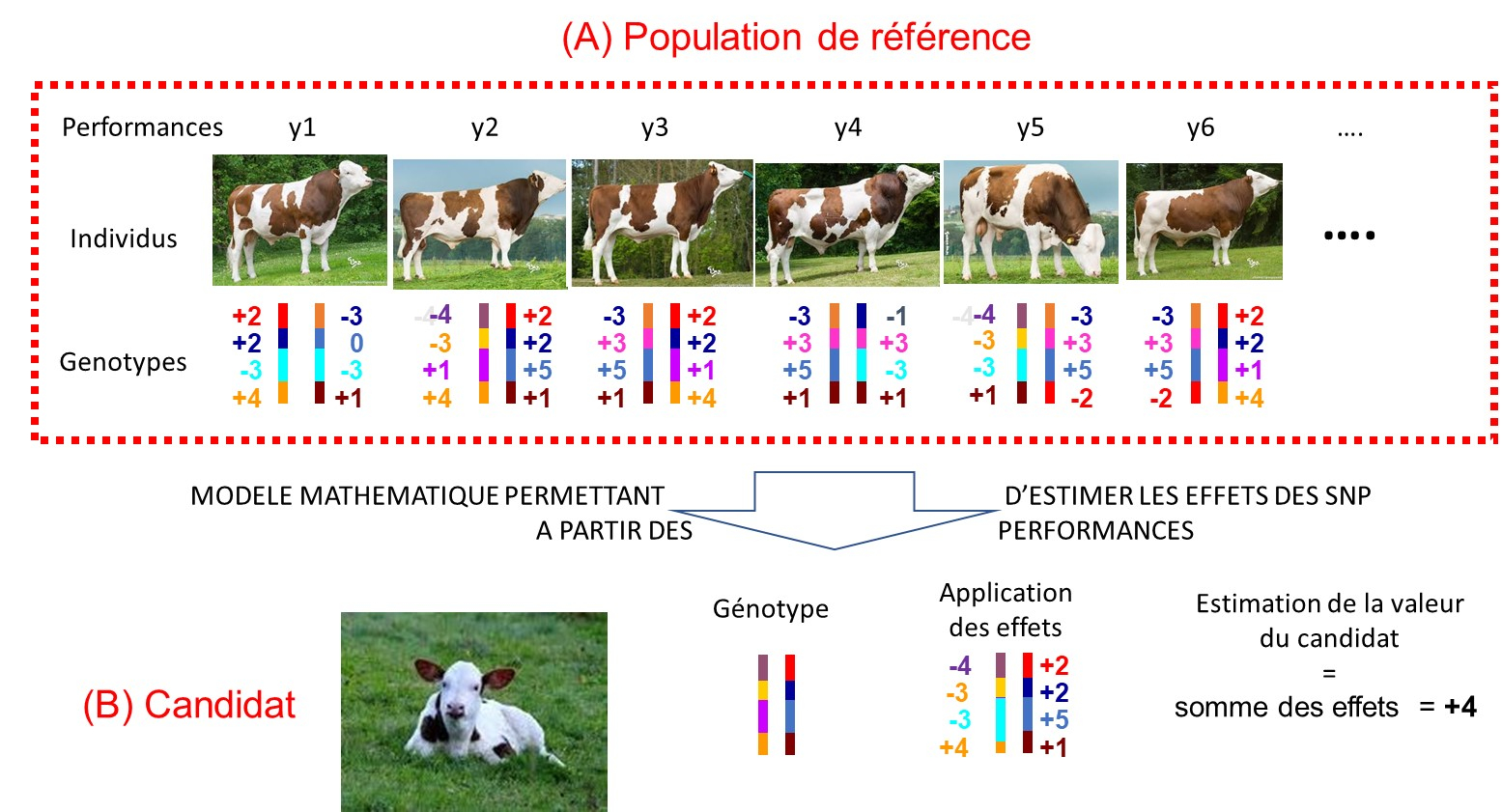
Dans une population de référence, chaque individu est génotypé (détermination des SNP possédés) et phénotypé (analyse des performances pour différents traits). Un modèle mathématique permet de déduire l’effet des différents SNP sur le phénotype. Grâce à ces résultats, un éleveur peut estimer le potentiel des différents candidats de son troupeau en les génotypant. Il peut ainsi sélectionner les reproducteurs présentant les valeurs génétiques les plus élevées.
Facteurs d’efficacité des prédictions génomiques
La valeur génétique des individus, déduite des méthodes d’évaluation génomique présentée ci-dessus, n’est qu’une estimation, et peut être différente de la « vraie » valeur. Plusieurs facteurs affectent la précision des évaluations génomiques, notée R2, qui correspond au carré de R, la corrélation entre la valeur estimée et la valeur génétique vraie. Comme dans toute estimation statistique, la précision est d’autant meilleure que l’effectif de la population de référence est élevé. De façon similaire, la précision augmente avec l’héritabilité du caractère. En effet, plus l’héritabilité est forte, plus l’effet du milieu sur l’expression du caractère diminue et donc plus l’estimation des effets génétiques est précise. La figure 4 fournit la précision R2 pour un effectif et une héritabilité donnés, dans une population d’élevage standard 1.

Pour une valeur d’héritabilité donnée, plus la population de référence est importante et plus la précision de l’évaluation génomique est forte. Par ailleurs, la précision de l’évaluation augmente avec l’héritabilité du trait considéré.
Pour que les effets des marqueurs reflètent l’effet des mutations causales, il faut que marqueurs et variants causaux soient en déséquilibre de liaison, c’est-à-dire qu’ils soient physiquement proches et donc peu affectés par le brassage intrachromosomique. Plus la diversité génétique d’une population est importante, plus les segments conservés entre individus sont petits, plus les marqueurs doivent être nombreux, et plus la population de référence doit être grande pour estimer précisément leurs effets. De façon similaire, plus le génome est grand (en nombre de recombinaisons par méiose, ou Morgan), plus les marqueurs doivent être nombreux, et plus la population de référence doit être grande. Ce dernier facteur est cependant assez théorique car chez les mammifères, la longueur du génome est comparable d’une espèce à l’autre.
Le nombre d’effets de marqueurs à estimer étant très élevé et souvent supérieur au nombre de données dans la population de référence, il faut utiliser des méthodes d’estimation spécifiques. Ces méthodes ont fait l’objet de nombreux développements. Nous n’entrerons pas ici dans leur détail. La méthode la plus courante est celle du BLUP génomique (ou GBLUP) 1.
Enfin, il convient de se souvenir que la précision de l’évaluation dépend fortement de l’apparentement entre populations de référence et candidats. En effet, les effets statistiques des marqueurs s’érodent rapidement avec les générations. Il est donc essentiel que la population de référence soit représentative de la population des candidats et qu’elle soit renouvelée pour « suivre » l’évolution des candidats : avec les méthodes actuelles, toute augmentation de distance (en termes de nombre de générations) induit une perte de précision.
Propriétés de la sélection génomique
Pour mesurer les conséquences de la sélection génomique, considérons la formule de prédiction du progrès génétique $\Delta G$, en supposant une population simple à générations séparées :
$$\Delta G = \frac{i σ_{g} R}{T}$$
avec :
- $i$ l’intensité de sélection (définie par la supériorité, mesurée en écart-type de l’index, des sélectionnés par rapport aux candidats) ;
- $σ_{g}$l’écart type génétique (égal au produit de l’écart type phénotypique par la racine carrée de l’héritabilité) ;
- $R$ la corrélation entre valeur génétique prédite et valeur génétique vraie ;
- $T$ l’intervalle de génération (défini par l’âge moyen des parents à la naissance de leurs descendants).
Si $σ_{g}$ est une constante du caractère, les paramètres $i$, $R$ et $T$ varient en fonction des méthodes de sélection.
La sélection génomique produit des évaluations précoces, la seule contrainte étant la disponibilité d’ADN. Une analyse dès la naissance est possible, voire éventuellement sur l’embryon. La sélection devient indépendante d’une mesure du phénotype sur les candidats, le reproducteur peut être utilisé dès qu’il est en âge de reproduire, ce qui permet de réduire l’intervalle de génération $T$.
La précision $R$ ne dépend que de la population de référence. Elle est donc potentiellement élevée si cette population de référence est de taille suffisante. Elle ne dépend plus du temps nécessaire à accumuler l’information phénotypique sur le candidat ou ses descendants, comme c’est le cas en sélection classique. L’avantage devient évident lorsque le caractère est non mesurable sur le candidat, coûteux à mesurer, tardif dans la vie ou incompatible avec le statut de reproducteur, toutes conditions rendant la sélection classique difficile et coûteuse. La précision obtenue est équivalente chez les mâles et les femelles, ce qui est un avantage considérable pour les caractères exprimés dans un seul sexe, comme la production laitière.
Enfin, l’intensité de sélection $i$ dépend surtout du nombre de candidats que l’on peut génotyper pour un budget donné, et donc du coût du génotypage. Lors de la comparaison économique entre sélection génomique et classique, un paramètre central est le rapport entre le coût du génotypage et celui du phénotypage.
Pour résumer, les gains permis par la sélection génomique sont de plusieurs types : une précision potentiellement élevée si la population de référence le permet ; un intervalle de génération qui n’est plus limité que par l’âge à partir duquel un animal peut se reproduire ; l’intensité de sélection peut être élevée si le coût du génotypage est faible. La situation est assez variable entre espèces et filières. Elle est généralement beaucoup plus favorable aux grosses espèces dont l’intervalle de génération peut être raccourci et pour lesquelles le coût du génotypage n’est pas trop limitant par rapport à la valeur de l’animal.
La sélection génomique a été très rapidement adoptée en bovins laitiers pour une raison principale : alors que la sélection classique repose sur le testage sur descendance qui est long (5 ans) et coûteux, la sélection génomique repose sur une caractérisation des reproducteurs dès la naissance, sans testage. C’est donc une solution particulièrement attractive en élevage laitier. Dans cette filière, par la diminution de l’intervalle entre générations, le progrès génétique peut être doublé sans augmenter le coût de la sélection.
Par ailleurs, les conditions initiales de mise en œuvre ont été facilitées par la disponibilité de populations de référence. Ainsi, chez les bovins laitiers, les premières populations de référence ont été constituées des taureaux testés sur descendance dans les années précédentes. Dans ce contexte, un index sur descendance est assimilable à une performance exprimée par le taureau, d’héritabilité égale à la précision de l’index, donc élevée. Ceci permet de bénéficier d’une bonne précision pour tous les caractères. Ainsi des milliers de taureaux testés ont été génotypés, permettant de prédire la valeur des jeunes candidats avec des R2 compris entre 0,5 et 0,7 pour plus de 40 caractères, y compris certains peu héritables comme la fertilité. Dans cette espèce, les phénotypes préexistaient de sorte que le coût de la population de référence initiale a été limité au coût du génotypage.
La sélection génomique s’est ainsi développée particulièrement vite chez les bovins laitiers. Elle est officielle en France depuis 2009 2. La sélection génomique a été une alternative au testage qui a vu sa pratique rapidement disparaître. Dès 2013, 70 % des inséminations dans les trois principales races laitières françaises (Holstein, Normande et Montbéliarde) étaient réalisées avec des taureaux évalués sur information génomique uniquement. Depuis 2011, le service est proposé à tout éleveur qui souhaite caractériser ses vaches.
Mais la situation n’est pas aussi simple dans les autres espèces. En évaluation classique, le coût de la sélection comprend le coût d’évaluation des candidats qui est proportionnel au nombre de reproducteurs à sélectionner. En évaluation génomique, il comprend le phénotypage et le génotypage de la population de référence en plus du génotypage des candidats. Il a donc une composante fixe, celle de la population de référence dont la taille détermine la précision. Pour les races dont les populations présentent de faibles effectifs, ce coût fixe constitue un frein à la mise en place. Au contraire, pour des grandes populations comme la race bovine Holstein, une population de référence de plusieurs dizaines de milliers d’individus est une solution réaliste et économiquement attractive.
De plus, dans les conditions actuelles de sélection génomique, la précision d’évaluation n’est élevée que lorsque les candidats sont fortement apparentés à la population de référence, ce qui impose de la renouveler constamment au cours des générations. Cette contrainte est d’autant plus forte que l’intervalle de génération est court.
Un point critique est le coût du génotypage. Ce coût intègre différentes composantes : prélèvement de tissus, extraction d’ADN, puce, travail de laboratoire, évaluation génétique. Le prix du génotypage a diminué progressivement du fait du progrès des technologies, de l’augmentation des volumes et de la concurrence entre fabricants. Une approche pour diminuer le coût a été l’utilisation de puces de plus basse densité, contenant moins de marqueurs et moins chères 3. Cette stratégie demande une organisation et un travail bio-informatique d’imputation, en vue de reconstituer statistiquement l’information manquante avec la meilleure précision possible. Utilisée chez les bovins de 2012 à 2018, elle a permis un développement rapide du génotypage. La mise en place d’un consortium européen d’achat de puces a permis de réduire les prix grâce à l’important volume, et depuis 2019, la puce utilisée est de moyenne densité. La large diffusion de cette puce permet de la remettre à jour régulièrement et donc d’inclure de nouveaux tests issus des travaux de recherche, augmentant l’intérêt de son utilisation. À l’avenir, la solution de génotypage pourrait changer en fonction des évolutions technologiques, en particulier du séquençage. Cependant la puce est une technologie donnant toute satisfaction à un prix raisonnable et il est probable que ce changement ne soit donc pas immédiat, contrairement à d’autres espèces.
Implémentation de la sélection génomique
L’utilisation de cet outil entraîne des conséquences importantes dans l’organisation de la sélection. Tout d’abord, il convient de trouver le meilleur compromis entre l’investissement dans la population de référence (qui détermine la précision) et le nombre de candidats génotypés (qui détermine l’intensité de sélection).
Chez les bovins, le compromis entre précision de l’évaluation et intervalle de générations a été profondément modifié. En sélection classique, les jeunes ont une précision d’évaluation faible et il est préférable d’attendre une meilleure précision avec l’arrivée des performances des descendants, au prix d’un âge élevé à l’utilisation. En sélection génomique, les reproducteurs sont diffusés le plus tôt possible pour diminuer l’intervalle de génération et profiter pleinement de l’évaluation précoce. Il a ainsi été rapidement démontré que le testage sur descendance n’était plus nécessaire 45. En effet, il est plus intéressant de réduire l’intervalle de génération en utilisant les taureaux dès qu’ils sont en âge de reproduire. Le coût d’un taureau mis sur le marché étant fortement diminué, il est rentable économiquement et intéressant génétiquement d’en utiliser un plus grand nombre qu’auparavant, chaque taureau n’ayant alors qu’une diffusion limitée dans le temps et en nombre de doses. Cette option est largement préférable : du fait du raccourcissement de l’intervalle de génération, le risque d’augmentation de consanguinité doit être compensé par un nombre de reproducteurs plus élevé 6. Par ailleurs, une offre de taureaux plus large satisfait mieux les besoins individuels de chaque éleveur.
Sélection pour de nouveaux caractères et évolution des objectifs de sélection
La sélection génomique d’un caractère est possible dès lors que l’on dispose d’une population de référence adaptée, en taille et en nature. En déconnectant l’obtention des phénotypes et l’évaluation des candidats, la sélection génomique offre donc une grande souplesse, pour les caractères difficiles à mesurer chez les candidats. Si un caractère est mesuré, il est sélectionnable.
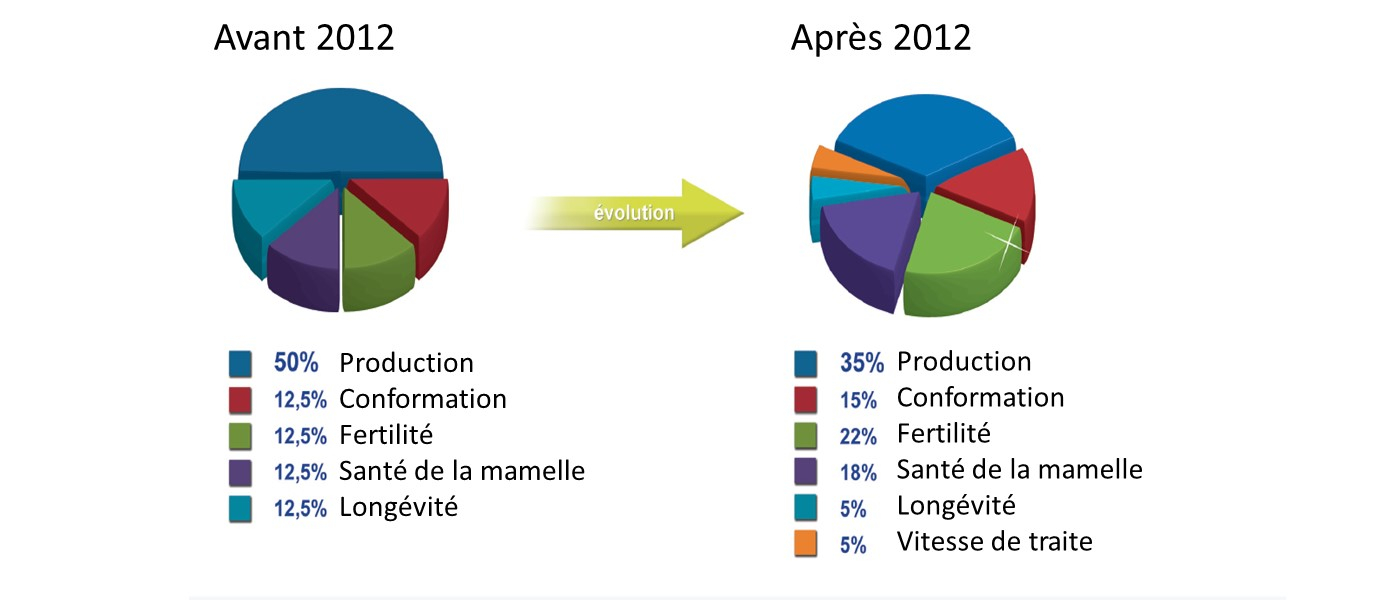
Par ailleurs, la sélection génomique engendre plus de progrès génétique, ce qui permet d’augmenter le nombre de caractères sélectionnés sans obérer les gains sur les autres caractères. La définition des objectifs de sélection a pu évoluer pour prendre en compte des besoins plus complexes (Boichard, 2013). Au cours des 40 dernières années, les objectifs de sélection initialement orientés sur la productivité ont progressivement intégré les caractères de qualité des produits puis d’adaptation des animaux. Aujourd’hui, les demandes se diversifient pour satisfaire les trois facettes de la durabilité : économiques, sociétales et environnementales (Figure 5).
Chaque fois que c’était possible, les sélectionneurs bovins ont cherché à tirer parti de sources de données existantes. Ainsi, les robots de traite constituent des systèmes privilégiés d’observation et de phénotypage des animaux (analyse du lait, débit de traite, poids des animaux…). La spectrométrie moyen infrarouge (MIR), déjà largement utilisée pour mesurer les taux butyreux et protéique du lait, peut être étendue à d’autres composants (profil en acides gras, protéines, minéraux, aptitudes fromagères) avec une précision suffisante pour des fins de sélection (Figure 6, 1). Avec plus de 20 millions d’analyses moyen infrarouge réalisées chaque année, un phénotypage à haut débit est possible avec un surcoût marginal. Les spectres moyen infrarouge permettent aussi de mesurer des signatures dans le lait de l’état physiologique (mobilisation corporelle), des troubles de santé (acétonémie), ou l’émission de méthane.

L’absorbance du lait peut être mesurée dans les infrarouges moyens (entre environ 2 et 50 µm). L’analyse du spectre obtenu permet de déduire des informations sur la composition du lait et sur l’état de la vache qui l’a produit.
Reproduit avec l'aimable autorisation de Marine Gelé.
Lorsque la sélection est réalisée dans une population commerciale, des données préexistantes, de gestion technique ou d’activité commerciale, peuvent être valorisées 1. Citons les données de troubles des sabots collectées lors du parage, les données du carnet sanitaire tenu par l’éleveur, les données de prophylaxie (par exemple, tests Elisa de paratuberculose) ou les caractéristiques de carcasse collectées en abattoir.
Des efforts très importants sont réalisés pour mesurer l’efficacité alimentaire. Ce caractère est essentiel parce que l’aliment représente le poste de charges le plus important de l’élevage et parce que des animaux plus efficaces rejettent moins d’effluents. La mesure de l’ingestion, qui demande des dispositifs de distribution individuelle d’aliments, est très coûteuse et divers partenaires ont mis en commun leurs données au niveau international pour constituer des populations de référence de taille suffisante 2.
Sélection génomique robuste
Les méthodes de sélection génomique actuelles ne fonctionnent bien que lorsque la population de référence est fortement apparentée aux candidats. Il faut donc reconstruire une population de référence spécifique à chaque population en sélection. Une conséquence est la difficulté à appliquer la sélection génomique dans les petites populations et l’absence d’intérêt à combiner plusieurs races pour gagner en précision.
À l’avenir, les méthodes devront donc être moins sensibles à l’apparentement. Ce problème essentiel n’est pas résolu à ce jour, même si des efforts de recherche importants sont consentis à l’échelle nationale et internationale. La solution repose sans doute sur l’identification des mutations causales, responsables de la variabilité génétique des caractères. Les travaux utilisent les données de séquence de génome complet d’un nombre élevé d’individus. La séquence doit être vue comme un génotypage exhaustif, contenant tous les polymorphismes du génome, y compris les polymorphismes responsables de la variabilité des caractères. Identifier quelques milliers de variants causaux parmi des dizaines de millions de polymorphismes de séquence est un problème statistique difficile qui demande des dispositifs de très grande taille. Comme le séquençage reste trop cher pour être généralisé, l’approche utilisée est la reconstitution statistique (ou imputation) de la séquence complète chez des animaux génotypés, à partir des séquences réalisées. Cette approche a motivé le projet 1000 bull genomes 3 qui permet de partager aujourd’hui plus de 5000 séquences au sein du consortium. L’imputation étant appliquée à des dizaines de milliers d’individus génotypés et phénotypés, le résultat est un énorme dispositif étudié par analyse d’association (4 par exemple). Une fois les mutations causales identifiées, l’évaluation génétique devient une tâche beaucoup plus simple, d’autant que ces variants sont ajoutés à la puce de génotypage. Si les effets de ces mutations sont au moins partiellement conservés entre fonds génétiques, l’évaluation devient universelle et robuste au manque d’apparentement.

Autres applications du génotypage
Chez les bovins, le génotypage devrait se développer très fortement, et concerner l’ensemble des génisses du troupeau. Associée à l’utilisation de semence sexée, cette pratique permet de renouveler le troupeau à partir de la moitié du cheptel choisie par l’éleveur, et d’appliquer à la seconde moitié une politique de reproduction autre, par exemple le croisement ou la production de femelles pour la vente. Grâce à cette pression de sélection disponible chez les femelles, à la bonne précision des index femelles pour tous les caractères, ainsi que la gamme nettement plus large de reproducteurs mâles disponibles, des objectifs de sélection définis à l’échelle de l’élevage et s’écartant sensiblement de l’objectif général de la population deviennent réalistes. Pour la première fois, il est proposé une solution à la question récurrente de l’adaptation de la sélection aux souhaits individuels des éleveurs ou aux conditions locales.
De nouvelles applications voient le jour. De nouveaux plans d’accouplements peuvent être construits intégrant des informations génétiques précises sur plusieurs dizaines de caractères. Les tares peuvent être éliminées de façon volontariste et rapide. L’apparentement vrai entre individus est mesuré, permettant d’orienter les accouplements pour minimiser la consanguinité. La perte de variabilité liée à la sélection peut être limitée en favorisant l’originalité génétique ou en évitant la perte d’allèles importants mais rares.
Conclusion
La sélection génomique a révolutionné l’activité de sélection des vaches laitières, en modifiant les méthodes d’évaluation, la gestion des programmes de sélection, la définition des objectifs de sélection, la prise en compte de caractères nouveaux, et la conduite des troupeaux. Cette évolution n’est pas terminée et beaucoup d’innovations restent à venir. Cette approche s’est développée dans d’autres espèces un peu plus récemment, chez les animaux comme chez les plantes et devient la norme dans le domaine de la sélection.