
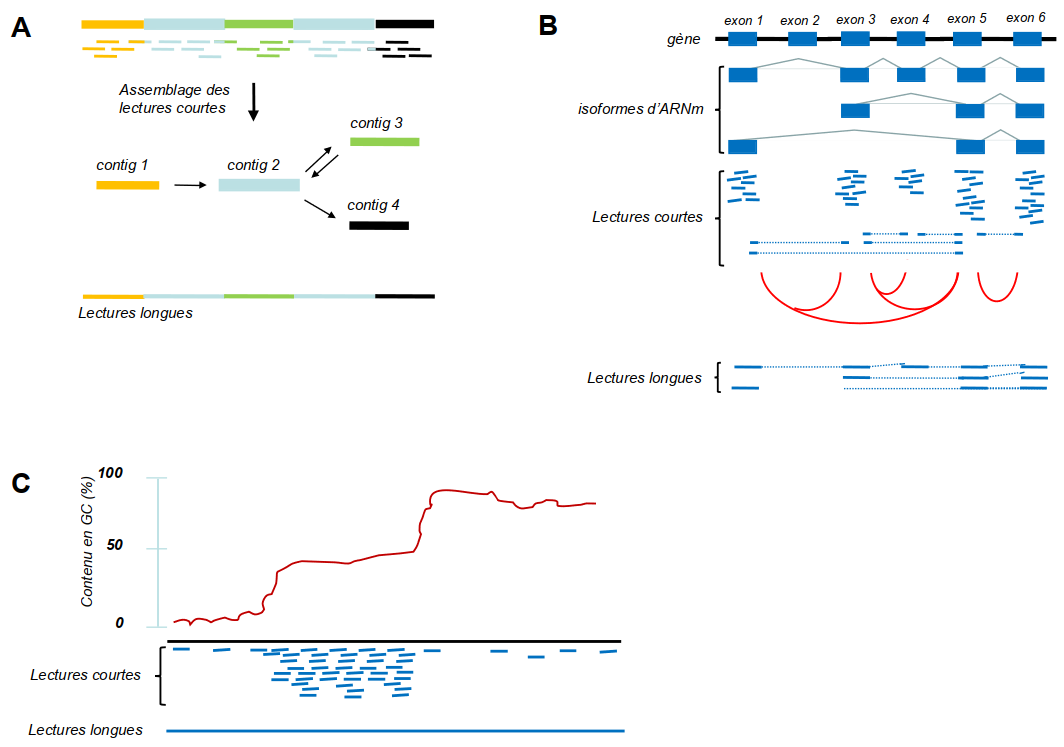
(A) Exemple qui montre le problème des régions répétées (en bleu clair) dans un génome, qui ne peuvent être positionnées à des endroits uniques avec des lectures courtes (NGS). Des lectures qui se situent à l’intérieur de ces régions seront assemblées en un seul contig. La région entre les répétitions (vert) peut être placée en amont ou en aval de ce contig bleu (illustré par les flèches en double-sens), ce qui génère une ambiguïté. Par contre, des lectures longues (long reads, TGS) qui traversent ces régions répétées ne laissent aucune ambiguïté. (B) Plusieurs transcrits (isoformes) peuvent être générés à partir d’un seul gène par épissage alternatif. Des lectures courtes de ces isoformes donneront des lectures à l’intérieur des exons présents dans le mélange (lignes continues) ainsi que des lectures qui chevauchent les jonctions entre les exons (lignes interrompues). Ainsi, les évènements d’épissage alternatif seront détectés ; les jonctions exon-exon détectées dans le mélange sont indiquées par des lignes rouges. Toutefois, les informations concernant les combinaisons des jonctions exon-exon dans les transcrits individuels manquent. Des lectures longues qui couvrent les transcrits entiers fournissent ces informations. (C) Les méthodes NGS dépendent de l’amplification par PCR, ce qui introduit des biais dans des régions pauvres en GC (à gauche de la courbe) ou très riche en GC (à droite). Par conséquent, ces régions seront peu couvertes. Les technologies de troisième génération PacBio et nanopore n’ont pas besoin de l’amplification PCR et présentent donc beaucoup moins de biais avec ce type de régions.


{kind=link}